Multiscale SVD, K planes and geometric wavelets November 30, 2010
Posted by Sarah in Uncategorized.Tags: dimensionality reduction, geometric wavelets, high dimensional data, mauro maggioni, multiscale methods
add a comment
I went to the applied math talk by Mauro Maggioni today; here are notes from the presentation.
Multiscale SVD
We often have to deal with high-dimensional data clouds that may lie on a low-dimensional manifold. Examples: databases of faces, collections of text documents, configurations of molecules. But, we don’t know a priori what the dimension of the manifold is. So we ned some mechanisms for estimating that, in the situation where we have noise in the data.
Some terminology: the data points are 

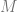

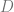
Previous work at estimating dimensions generally falls into two categories. One is volume-based (the number of points on the manifold confined within a ball should grow as 

Maggioni’s alternative is multiscale SVD. We fix a point. The noise around the manifold looks like a hollow tube — most of the noise is concentrated at a radius of 
The assumption about the data is that the tangent covariance grows differently (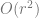

The result is that if 

One interesting fact is that many real-life data sets have dimensionality that varies. A database of text documents, for instance, is low-dimensional in some regions, and very, very high-dimensional in others. (We measure dimensionality locally, so there’s no reason in principle that it shouldn’t vary.)
Measures supported on K planes
Sometimes high-dimensional data is supported on a set of planes 
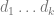
Maggioni and collaborators developed an algorithm for doing this.
1) Draw 




2. Construct an affinity matrix, with the (i, j)th coordinate

This is almost a matrix composed of zeros and ones — either a point is on a plane (in which we get one) or a point is not on that plane (in which case we get 0 because the distance is large.) In practice, with noise and curvature, it’s not quite binary, but it’s close.
3. Denoise and cluster this matrix, and find updated estimates for the planes from this.
Tested on a face database, this worked very well. It misclassified only 3 faces out of 640. What’s remarkable here is that the Yale Face Database used had 64 different photos of each person, taken at different angles, different lighting conditions, etc. This has always been a hard problem for computer vision: how do you recognize that two pictures are the same person viewed frontal and profile, while two other pictures are of two different people? Apparently, this is a solution to such heterogeneity problems.
Geometric wavelets
The problem of dictionary learning is as follows. Given 
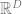
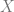
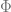
where 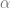

There’s a tradeoff here between the size of
One way of doing this is something called geometric wavelets. (Paper here. Shorter, more descriptive paper with cool picture here.)
Given a manifold, we partition it into a dyadic tree. We do principal components analysis on the coarsest scale and get a plane; then we divide that into two smaller subsets, do PCA on each of them, and get two new planes. For each plane, at the center point of that cube in the manifold grid, we have a tangent vector 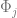

There’s a fast algorithm for computing this, very like the wavelet transform, except for a point cloud rather than a function. This is useful for compressing databases, analyzing online data, and so forth.
The idea is very like Peter Jones’ construction of beta numbers (summary here) except that it may be more efficient in terms of storage. More on geometric wavelets from Dan Lemire.
Vision without categories? November 17, 2010
Posted by Sarah in Uncategorized.Tags: AI, computer vision, machine learning
add a comment
I’d just like to mention that I’ve come across Tomasz Malisiewicz’s blog on machine learning and computer vision, and I’m hooked. You should be too.
There’s the usual panoply of links to interesting papers, but then there’s also Tomasz’s radical idea for reimagining computer vision using a memex instead of a set of categories. He thinks that the “vision problem” will be solved by something much closer to actual AI than is generally considered necessary today. His ideas are informed by Wittgenstein and Vannevar Bush as well as contemporary research. It sounds interesting, to say the least. Then there’s also Tomasz’s stirring (if somewhat intimidating) advice to students and researchers to be Renaissance men and look beyond the A+ and the well-received publication. All in all, very worth reading.
(Sensible Sarah says: “Hey, wait a minute! I thought I was a math student — what’s up with all this vision stuff? And I have a qual to pass in a month!” Sensible Sarah throws up her hands in dismay.)
The Custom Essay Man November 16, 2010
Posted by Sarah in Uncategorized.Tags: academia
3 comments
I was somewhat disturbed to read this article in the Chronicle of Higher Education. It’s written by a man who writes papers for a custom-essay company; students pay him to write their papers for them. Obviously it’s sad to see how common academic dishonesty is. But what really shocked me was something else.
A lot of “Ed Dante”‘s customers (he goes by a pseudonym) are in graduate or professional school. And apparently they’re really terrible writers. When they write him asking him for help, it’s something like “You did me business ethics propsal for me I need propsal got approved pls can you will write me paper?” I have to wonder — why are these people in graduate school in the first place?
I don’t mean that pejoratively. I don’t think you’re inferior as a person if you’re bad at writing or not gifted at academics. But look. I’m a grad student myself. I’m here because I want to be a mathematician. While the future is uncertain for all of us, I wouldn’t be here if I thought that was a completely unrealistic goal. If I were so overwhelmed by the work here that I was tempted to pay someone to do it for me, and if I’d already tried tutors, adjusting my sleep and study schedule, etc. then I’d start reevaluating my plans. It would be insane not to! The way I see it, going to graduate school is a decision that has to be justified — you should do it only if you think it’ll help you in the long run.
If you can’t write your own briefs in law school, you really think you’re going to be a successful lawyer? If you can’t write your own PhD thesis, do you really think you have any chance to make it in academia?
This article really makes me worry that lots of people are going for extra degrees just for the sake of doing it, or to escape the job market, and not because they’re really pursuing a passion or talent that has a realistic chance of paying off. That’s disturbing — it seems like a bad sign for the economy as a whole.
Shape Google November 15, 2010
Posted by Sarah in Uncategorized.Tags: content-based image retrieval, image processing, laplace-beltrami operator, machine learning
2 comments
Currently reading this paper by Alex Bronstein et al.
The idea here is to make searchable databases for shapes (2d and 3d objects) in the same way a text engine responds to search queries.
There are two main parts to this task: feature detection, and feature description. Different methods can be employed to define what a feature is; a dense descriptor just selects all the points in the image as descriptors, but there are other possibilities. SIFT looks for local maxima of the discrete image Laplacian that persist through different scales. MSER finds level sets that show the smallest variation of area when traversing the level-set graph.
Feature description aims to produce a “bag of words” from the features, by performing vector quantization on the feature space. Two images can then be compared by comparing their bags of features with plain old Euclidean distance.
There are extra challenges if we want to do this with 3d objects rather than images: for one, conformations of 3d objects (like a body in different poses) are much more complicated than the (usually affine) transformations seen on a given image. Also, while images are typically represented as matrices of pixels, 3d objects can be represented as meshes, point clouds, level sets, etc, so computations have to be portable between formats. Also, 3d objects don’t have a universal system of coordinates.
The feature description process used by the authors is based on heat kernel signatures.
Recall that the heat kernel 
The heat kernel can also be seen as the transition density function of a Brownian motion.
For any point on the surface, we give its heat kernel signature as
This is invariant under isometric deformations of the space, since it depends only on the Riemannian metric. It captures local information in a small neighborhood of x for small t, and global information for large t. It can be proven that any continuous map preserving the heat kernel signature must be an isometry. And computing it depends on computing the eigenvalues of the Laplacian, which can be done with various formats of representing 3d shapes.



So, since the eigenvalues of the Laplacian decay exponentially, we can truncate this sum for computation of the heat kernel.
In the discrete case, instead of the Laplacian we would use a discretization of the form
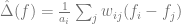
After vector quantization to get a bag of features, the authors generalize this notion to a spatiall sensitive bag of features:
giving a matrix that represents the distribution of nearby words.

From there, we can compare these matrices by embedding them into a Hamming Space. (Hamming distances happen to be very quick to compute on modern CPU architectures.
ShapeGoogle was tested against various possible transformations of shapes (isometries, topology changes, holes, noise, scale changes) and performed well, outperforming other methods like Shape DNA, part-based bag of words, and clock matching bag of features.
It’s an interesting project, and I suspect that the ability to search shape databases will prove useful. Here’s a list of current content-based image retrieval search engines: both Google and Bing use these methods (as opposed to only looking at metadata.)
Alternating methods for SVD November 9, 2010
Posted by Sarah in Uncategorized.Tags: dimensionality reduction, pca, random matrix theory
1 comment so far
Last week’s applied math seminar was Arthur Szlam, talking about alternating methods for SVD. I’m putting up some notes here; several results are presented without proof.
Given an m x n matrix A, we want to find the best rank k approximation to A.
There is an explicit solution to this problem, known as the singular value decomposition. We write
where 

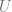




where the “hat” means taking the first k columns of each matrix.
This is the best rank-k approximation, both in the sense of Frobenius norm and operator norm.


However, if 
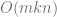
We fix k, and a small oversampling parameter p, and let 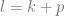
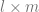
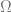
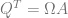
Calculate the SVD, 
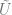
Why does this work?
Well, pretend A is really of rank 5, for instance. Hit A with a random matrix. It is unlikely that any vector will be in the kernel of A. Whatever's left is in the range. So we're very likely to have the full range of A; we probably preserve the SVD. However, in real life we don't have a known rank k matrix.
What we have is a guarantee of quality, in terms of the decay of the singular values:
![E ||A - A Q Q^T|| \le [ 1 + \sqrt{\frac{k}{p-1}} + \frac{e \sqrt{k + p}}{p} \sqrt{m-k}] \sigma_{k +1}](https://s0.wp.com/latex.php?latex=E+%7C%7CA+-+A+Q+Q%5ET%7C%7C+%5Cle+%5B+1+%2B+%5Csqrt%7B%5Cfrac%7Bk%7D%7Bp-1%7D%7D+%2B+%5Cfrac%7Be+%5Csqrt%7Bk+%2B+p%7D%7D%7Bp%7D+%5Csqrt%7Bm-k%7D%5D+%5Csigma_%7Bk+%2B1%7D&bg=ffffff&fg=666666&s=0&c=20201002)
Here the expected value is taken over the random Gaussian draw, the norm is the operator norm, and 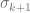

This actually happens, unfortunately. For example, in term document matrices, where a collection of text documents form the rows, and words form the columns, with a word count in each matrix entry indicating how often a word was used in each document. (A little imagination should indicate the importance of these kinds of matrices for semantic analysis.) These matrices are sparse and large, but their singular values decay slowly. So what can we do here?
We hit
Now we have a new estimate, depending on the power q.

![E ||A - A Q_q Q_q^T|| \le [1 + \sqrt{\frac{k}{p-1}} + \frac{p \sqrt{k + p}}{p} \sqrt{m-k}]^{1/2q + 1} \sigma_{k+1}](https://s0.wp.com/latex.php?latex=E+%7C%7CA+-+A+Q_q+Q_q%5ET%7C%7C+%5Cle+%5B1+%2B+%5Csqrt%7B%5Cfrac%7Bk%7D%7Bp-1%7D%7D+%2B+%5Cfrac%7Bp+%5Csqrt%7Bk+%2B+p%7D%7D%7Bp%7D+%5Csqrt%7Bm-k%7D%5D%5E%7B1%2F2q+%2B+1%7D+%5Csigma_%7Bk%2B1%7D&bg=ffffff&fg=666666&s=0&c=20201002)
This works, but it can be memory intensive to save all the intermediate powers. This is where the "alternating" method comes in.
Here we look at a related problem: matrix completion. You're given a subset of the entries of a matrix A, and you know A is low rank. How do you fill in the rest of the entries? The simplest approach is alternating least squares.
Write 
Alternate between updates of P and Q:
These are least-squares problems, and can be solved explicitly using
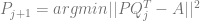

Step 1: form 
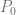
Step 2: form 
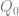
(a QR-decomposition, with Q orthogonal and R upper triangular.)
Step 3: iterate for


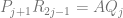
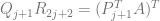
Coming back to our own problem, we can use the same formula to calculate 

This turns out to work well in practice; the example set was a database of labeled faces, which have the first 20 eigenvalues decaying fast, then the next decaying very slowly. This kind of alternating SVD works well for faces.
Remember, Remember the Fifth of November November 5, 2010
Posted by Sarah in Uncategorized.Tags: algebraic geometry
2 comments
Guy Fawkes Day. It’s a good day for radical ideals. No, not that kind! This kind.
I’m currently reading Charles Siegel’s series of posts on Algebraic Geometry from the beginning and I highly recommend. It’s some of the clearest, loveliest writing ever, and it’s got me really interested in the topic.
Advice for calculus students November 3, 2010
Posted by Sarah in Uncategorized.Tags: grad life, teaching
5 comments
I am now a TA holding office hours for some calculus classes, and I actually enjoy it a lot. I’m generally impressed with the students. General advice that ought to hold if you’re taking an intro calc class:
1. Don’t freak out because a problem is taking a long time and seems unfairly hard. You’ll say “There must be some mistake!” No, there isn’t. This isn’t high school; you’re being taught by professors, who don’t always know how to gauge the right difficulty level. They do tend to underestimate how long it takes to finish your homework. Also, calculus is actually harder than high school math. If you have to go through a lot of computations and false steps — don’t worry! That’s what math is actually like!
2. I do not have magical TA superpowers of Mathematica. Most of the time, if you ask me for help, I’m going to look at the example on your worksheet and look in the help documentation. You could do that too! The xkcd Tech Support Cheat Sheet is relevant here.
3. L’Hopital’s rule is your friend. Seriously. So is big-O notation. These will save your bacon.
4. 90% of mistakes in multivariable calc result from not drawing pictures. Draw a picture. You are never too cool to draw a picture.
Caratheodory Kernel November 3, 2010
Posted by Sarah in Uncategorized.Tags: analysis, conformal maps
add a comment
Last fall I had the opportunity to go to the Cryo-EM mini-symposium at the Columbia Medical Center, which was an interesting experience — a mix of biologists, computer scientists, and mathematicians. One comment from a biologist stuck with me: sometimes, given that equipment has only finite precision, microscopic images can lead to confusion as to the number of connected components. If we’re thinking about a molecule, it’s quite important to know whether we’re looking at a protrusion or a separate component. With imprecise equipment, there’s a chance of getting it wrong. But how do you know when?
The question bugged me for a while. Connected components seem like a “topological” property, but it seems that you ought to be able to talk about this more directly, without appealing to homology.
Posing this question more specifically, suppose you have a connected domain E. To make life simple, let’s suppose it’s in the plane. And suppose we approximate it at different levels of “coarseness” — perhaps we overlay a grid of squares of side length r, and let E_r be the domain that contains a square precisely when the intersection between E and the square has area at least 1/2 r^2. For some sets E, there is some scale E_r that becomes disconnected; for example, if E is dumbbell-shaped, eventually at some scale it will “split” into two components. How do you know when it’s going to do this?
I asked a professor about this, and it turns out it’s a classical question, and the relevant notion is something called the Caratheodory Kernel, developed in 1912.
Let B_n be a sequence of simply-connected domains of the z-plane containing a fixed point z_0. If there exists a disc
belonging to all
, then the kernel of the sequence
is the largest domain B containing z_0 and such that for each compact set E belonging to B there is an N such that E belongs to all B_n, for n larger than N.
A largest domain is one which contains any other domain having the same property. If there is no such a disc, then by the kernel of the sequence B_n, one means the point z_0 (in this case one says that the sequence B_n has a degenerate kernel). A sequence of domains B_n, converges to a kernel B if any subsequence of B_n has B as its kernel.
Link.
It’s a theorem of Caratheodory that a sequence of functions f_n with positive derivatives at z_0, conformally mapping the unit disc to B_n respectively and are regular and univalent in the disc |z – z_0| < 1 then in order for the sequence f_n to converge in the disc to a finite function, it is necessary and sufficient that the kernels converge to either a point or a domain containing more than one boundary point.
(
