Harmonic Analysis: The Hilbert Transform September 30, 2010
Posted by Sarah in Uncategorized.Tags: harmonic analysis, hilbert transform
add a comment
I’ve really been enjoying my harmonic analysis class and I thought I’d write up some recent notes.
The Poisson kernel, 
This is the real part of a holomorphic function. Now, what are the properties of that holomorphic function?
We define the Herglotz kernel as
where 
As 


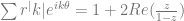

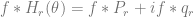
Now, we can write 
similar to the Poisson kernel, except for the sign function. Summing this series,

This conjugate function of 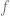





The Hilbert transform can be shown to be bounded for all 
If we let 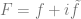
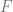
Current reading: neuroscience September 30, 2010
Posted by Sarah in Uncategorized.Tags: AI, neuroscience
7 comments
Right now my “interests” are supposed to be limited to passing quals. Fair enough, but I’m also persistently trying to get a sense of what math can tell us about how humans think and how to model it. Except that I don’t actually know any neuroscience. So I’ve been remedying that.
Here’s one overview paper that goes over the state of the field, in terms of brain architecture and hierarchical organization. Neurons literally form circuits, and, in rough outline, we know where those circuits are. We can look at the responses of those circuits in vivo to observe the ways in which the brain clusters and organizes content: even to the point of constructing a proto-grammar based on a tree of responses to different sentences. I hadn’t realized that so much was known already — the brain is mysterious, of course, but it’s less mysterious than I had imagined.
Then here’s an overview paper by Yale’s Steve Zucker about image detection using differential geometry. In his model, detection of edges and textures is based on the tangent bundle. Apparently, unlike some approaches in computational vision, this differential geometry approach has neurological correlates in the structure of the connections in the visual cortex. The visual cortex is arranged in a set of columns; the hypothesis is that these represent 
What is a quantum vector space? September 24, 2010
Posted by Sarah in Uncategorized.Tags: algebra
add a comment
I went to the Friday grad seminar — this one by Hyun Kyu on the quantum Teichmuller space. (Here’s his paper, which I haven’t read as of now.) I thought it might be helpful to learn some background about this whole “quantum” business.
One way of thinking about the ordinary plane is to consider it the algebra freely generated by the elements x and y subject to the commutation relationship yx = xy. Now, what if we alter this description to instead have yx = qxy? This defines something known as the quantum plane. Here, q is an element of the ground field. Obviously, except when q = 1, this is a non-commutative algebra. For any pair of integers i and j, we have
We can define quantum versions of lots of things — for example, 

ab = 2ba, bc = cb, cd = q dc, ac = q ca, bd = q db, and ad-da = (q – 1/q)bc.
The “quantum” here is in the mathematical sense of a non-commutative deformation of a commutative algebra.
More on the subject: “What is a Quantum Group?”
See Your Group September 23, 2010
Posted by Sarah in Uncategorized.Tags: grad life
2 comments
Because I am a geek, and because I love my hometown, I had a T-shirt made.


The inspiration, of course, is the storied Valois Cafeteria in Hyde Park, where you can “see your food.”

It’s a local institution, known for comfort food and more recently famous as an Obama favorite.
Johnson-Lindenstrauss and RIP September 10, 2010
Posted by Sarah in Uncategorized.Tags: compressed sensing, dimensionality reduction
2 comments
Via Nuit Blanche, I found a paper relating the Johnson-Lindenstrauss Theorem to the Restricted Isometry Property (RIP.) It caught my eye because the authors are Rachel Ward and Felix Krahmer, whom I actually know! I met Rachel when I was an undergrad and she was a grad student. We taught high school girls together and climbed mountains in Park City, where I also met Felix.
So what’s this all about?
The Johnson-Lindenstrauss Lemma says that any p points in n-dimensional Euclidean space can be embedded in 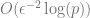


The Restricted Isometry Property, familiar to students of compressed sensing, is the property of a matrix 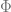
for all sufficiently sparse vectors 
The relevance of this property is that these are the matrices for which 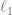
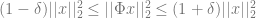
Now these two concepts involve equations that look a lot alike… and it turns out that they actually are related. The authors show that RIP matrices produce Johnson-Lindenstrauss embeddings. In particular, they produce improved Johnson-Lindenstrauss bounds for special types of matrices with known RIP bounds.
The proof relies upon Rademacher sequences (uniformly distributed in [-1, 1]), which I don’t know a lot about, but should probably learn.
[N.B.: corrections from the original post come from Felix.]
Concreteness September 5, 2010
Posted by Sarah in Uncategorized.Tags: grad life
add a comment
A friend sent me a quote from Don Zagier:
Even now I am not a modern mathematician and very abstract ideas are unnatural for me. I have of course learned to work with them but I haven’t really internalized it and remain a concrete mathematician. I like explicit, hands-on formulas. To me they have a beauty of their own. They can be deep or not. As an example, imagine you have a series of numbers such that if you add 1 to any number you will get the product of its let and right neighbors. Then this series will repeat itself at every fifth step! For instance, if you start with 3, 4 , then the sequence continues: 3, 4, 5/3, 2/3, 1, 3, 4, 5/3, etc. The difference between a mathematician and a nonmathematician is not just being able to discover something like this, but to care about it and to be curious about why it’s true, what it means, and what other things in mathematics it might be connected with. In this particular case, the statement itself turns out to be connected with a myriad of deep topics in advanced mathematics: hyperbolic geometry, algebraic K-theory, the Schrodinger equation of quantum mechanics, and certain models of quantum field theory. I find this kind of connection between very elementary and very deep mathematics overwhelmingly beautiful. Some mathematicians find formulas and special cases less interesting and care only about understanding the deep underlying reasons. Of course that is the final goal, but the examples let you see things for a particular problem differently, and anyway it’s good to have different approaches and different types of mathematicians.
It does seem true that some research mathematicians like concrete examples and some like generalities. I’m not sure how that distinction develops. But as a student I find it much easier to learn beginning with examples, as concrete and elementary as possible, and it’s hard for me to believe that anybody learns well otherwise.
Which is why it frustrates me when an introductory book dealing with representation theory begins by letting G be a group acting on a G-module over a field. It’s not that the generality isn’t useful in the subject. It just seems pedagogically lousy for a first-time reader.
Start instead with groups acting on finite-dimensional vector spaces over the complex numbers — in fact start with SO(3) — and you get a clear sense of the structure and original purpose of representation theory. You can see why it’s fundamentally about symmetry. You can even use (gasp!) polyhedra as an example. It’s so satisfying when a book goes down to the basic level. Call me childish — but I think we all start out as children before we work up to greater sophistication. (The book is Shlomo Sternberg’s Group Theory and Physics and it really is wonderful.)
