Church: a language for probabilistic computation October 23, 2010
Posted by Sarah in Uncategorized.Tags: AI, computer science
3 comments
As a novice with some interest in applied areas, it happens all too often that I fall in love with an idea about perception/cognition/data analysis, and find out only later “Oh wait, that wasn’t actually math! And I’d have to do so much background reading in a completely different field to understand it!” I’ve experienced “Oh wait, I’m not an electrical engineer!”, “Oh wait, I’m not a neuroscientist!”, and “Oh wait, I’m not a statistician!”
Well, today is the day I say “Oh wait, I’m not a computer scientist!”
The idea that caught my attention is probabilistic computing. We often want to build a machine that can make predictions and build models (a computer that can diagnose medical symptoms, or predict which creditors will default, or even, dare we whisper, an AI). This is essentially a Bayesian task: given some data, which probability functions best explain it? The trouble is, computers are bad at this. For the most part, they’re built to do the opposite task: given probability distributions and models, simulate some data. Generating probability functions and finding the best one can be prohibitively expensive, because the space of probability functions is so large. Also, while the computational complexity of evaluating f(g(x)) is just f + g, the computational complexity of composing two conditional probability distributions B|A and C|B is
ΣB P(C, B|A)
whose computational time will grow exponentially rather than linearly as we compose more distributions.
Church, a language developed at MIT is an attempt to solve this problem. (Apparently it’s a practical attempt, because the founders have already started a company, Navia Systems, using this structure to build probabilistic computers.) The idea is, instead of describing a probability distribution as a deterministic procedure that evaluates the probabilities of different events, represent them in terms of probabilistic procedures for generating samples from them. That is, a random variable is actually a random variable. This means that repeating a computation will not give the same result each time, because evaluating a random variable doesn’t give the same result each time. There’s a computational advantage here because it’s possible to compose random variables without summing over all possible values.
The nice thing about Church (which is based on Lisp, and named after Alonzo Church) is that it allows you to compose practically any query without significantly increasing runtime. “What is the probability of A and B or C and not D given that X and Y and not Z?” and so on.
The PhD dissertation that introduced Church is where I started, but it’s actually much clearer if you learn about it from the interactive tutorial. The tutorial is really a beautiful thing, well-written to the point of addictiveness. It is completely accessible to just about anyone.
Simultaneous Uniformization Theorem October 23, 2010
Posted by Sarah in Uncategorized.Tags: geometry, topology
add a comment
The other day, in the graduate student talks, Subhojoy was talking about the Simultaneous Uniformization Theorem. It was a nice treat because I used to be really into geometric topology (or at least as much as an undergrad with way too little background could.)
The big reveal is
but most of the talk, naturally, goes into defining what those letters mean.

The Riemann Mapping Theorem says that any simply connected set 

A Riemann Surface is a topological surface with conformal structure: a collection of charts to the complex plane such that the transition maps are conformal.
The first version of the Uniformization Theorem says that any simply-connected Riemann surface is conformally equivalent to the Riemann sphere (or complex plane or unit disc; these are all equivalent.)
The second, more general version of the Uniformization Theorem says that any Riemann surface of genus 
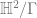
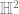
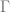

To understand this better, we should observe more about the universal cover of a Riemann surface. This is, of course, simply connected. Its deck transformations are conformal automorphisms of the disc. But it can be proven that conformal automorphisms of the disc are precisely the Mobius transformations, or functions of the form

This implies that the automorphism group of 
Now observe that there’s a model of the hyperbolic plane on the disc, by assigning the metric

And, if you were to check, it would turn out that conformal transformations on the disc preserve this metric.
So it begins to make sense; Riemann surfaces are conformally equivalent to their universal covering space, modulo some group
Now we can define Fuchsian space as

It’s the set of maps from the fundamental group of a surface to
And we can define Teichmuller space as the space of marked conformal structures on the surface S.
This is less enormously huge than you might think, because we consider these up to an equivalence relation. If 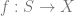

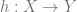

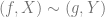
In fact, Teichmuller space is not that enormously huge: 
Here’s a picture of a pair of pants (aka a three-punctured sphere):

Here’s a picture of a decomposition of a Riemann surface into pairs of pants:

(Here’s a nice article demonstrating the fact. It’s actually not as hard as it looks.)
Now we generalize to Quasi-Fuchsian spaces. For this, we’ll be working with hyperbolic 3-space instead of 2-space. The isometries of hyperbolic 3-space happen to be 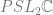
Instead of a Poincare Disc Model, we have a ball model; again, 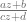
A quasiconformal function takes, infinitesimally, circles to ellipses. It’s like a conformal map, but with a certain amount of distortion. The Beltrami coefficient definds how much distortion:

Quasi-Fuchsian space, QF(S), is the set of all quasiconformal deformations of a Fuchsian representation. In other words, this is the space of all representations to
Now, the Simultaneous Uniformization Theorem can be stated:
the Quasi-Fuchsian space of a surface is isomorphic to the product of two Teichmuller spaces of the surface.
One application of this theorem is to hyperbolic 3-manifolds.
If 

In other words, we can think of a hyperbolic three-manifold as the real line, with a Riemann surface at each point — you can only sort of visualize this, as it’s not embeddable in 3-space.
The Simultaneous Uniformization Theorem implies that there is a hyperbolic metric on this 3-manifold for any choice of conformal structure at infinity.
This contrasts with the Mostow Rigidity Theorem, which states that a closed 3-manifold has at most one hyperbolic structure.
Together, these statements imply that any hyperbolic metric on 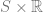
Partha Niyogi October 9, 2010
Posted by Sarah in Uncategorized.Tags: machine learning, partha niyogi
add a comment
Sad news: I found out this week that Partha Niyogi passed away. I never met him, but I read his papers and I admired his work.

Geometric Methods and Manifold Learning
Partha Niyogi, Mikhail Belkin
2 videos
Here’s a talk he gave in Chicago last year on manifold learning; it’s a lovely, complete overview of the problem and current algorithms (Isomap, LLE, Laplacian eigenmaps, diffusion distances.) Also at the MLSS conference site are many other talk videos about computational learning — Stephane Mallat, Emmanuel Candes, Guillermo Sapiro, etc. If I had infinite time I would just watch all of them.
The internet is really hard October 4, 2010
Posted by Sarah in Uncategorized.Tags: grad life
3 comments
I had dinner with some computer science students last night that involved this exchange:
CS kid 1: “Oh, I’m no good at math. You math people are too fancy for me.”
Me: “Well, you’re too fancy for me. I don’t even know how the internet works!”
CS kid 1: “Um, well…”
CS kid 2: “The internet is really hard.”
CS kid 1: “Most computer scientists don’t know how it works.”
CS kid 2: “I only know about it because that’s what I research.”
Me: “So I’m not just dumb?”
CS kid 1: “Nope. The internet is really hard.”
It’s been on my mind since I read this Douglas Rushkoff article. It’s a call to arms of sorts, an expression of dismay that we’ve become consumers of electronics that we don’t understand.
For me, however, our inability and refusal to contend with the underlying biases of the programs and networks we all use is less a threat to our military or economic superiority than to our experience and autonomy as people. I can’t think of a time when we seemed so ready to accept such a passive relationship to a medium or technology.
…
And while machines once replaced and usurped the value of human labor, computers and networks do more than usurp the value of human thought. They not only copy our intellectual processes–our repeatable programs–but they often discourage our more complex processes–our higher order cognition, contemplation, innovation, and meaning making that should be the reward of “outsourcing” our arithmetic to silicon chips in the first place. The more humans become involved in their design, the more humanely inspired these tools will end up behaving.
It hit home, because of course I use lots of devices and programs that I don’t understand. I consume much more than I produce. I can program — I can write a simulation in Matlab any time, and I could probably refresh my memory of C++ if I took a week or two — but I don’t know how the internet works. The techie ideal of having a DIY relationship to the technology I use is inspiring, but daunting. Maybe more daunting than it was in the 70’s, when Rushkoff was a new computer enthusiast; his ideal may have been easier to achieve when technology was simpler. I looked at an old CS textbook written in the 70’s — it wouldn’t have gotten me one-tenth of the way towards the goal of “understand all the technology you use today.”
I did find this non-technical intro to the structure of the internet useful, as a start. But I still wouldn’t say I understand how the internet works.
