Multiscale SVD, K planes and geometric wavelets November 30, 2010
Posted by Sarah in Uncategorized.Tags: dimensionality reduction, geometric wavelets, high dimensional data, mauro maggioni, multiscale methods
add a comment
I went to the applied math talk by Mauro Maggioni today; here are notes from the presentation.
Multiscale SVD
We often have to deal with high-dimensional data clouds that may lie on a low-dimensional manifold. Examples: databases of faces, collections of text documents, configurations of molecules. But, we don’t know a priori what the dimension of the manifold is. So we ned some mechanisms for estimating that, in the situation where we have noise in the data.
Some terminology: the data points are 

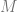

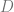
Previous work at estimating dimensions generally falls into two categories. One is volume-based (the number of points on the manifold confined within a ball should grow as 

Maggioni’s alternative is multiscale SVD. We fix a point. The noise around the manifold looks like a hollow tube — most of the noise is concentrated at a radius of 
The assumption about the data is that the tangent covariance grows differently (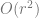

The result is that if 

One interesting fact is that many real-life data sets have dimensionality that varies. A database of text documents, for instance, is low-dimensional in some regions, and very, very high-dimensional in others. (We measure dimensionality locally, so there’s no reason in principle that it shouldn’t vary.)
Measures supported on K planes
Sometimes high-dimensional data is supported on a set of planes 
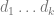
Maggioni and collaborators developed an algorithm for doing this.
1) Draw 




2. Construct an affinity matrix, with the (i, j)th coordinate

This is almost a matrix composed of zeros and ones — either a point is on a plane (in which we get one) or a point is not on that plane (in which case we get 0 because the distance is large.) In practice, with noise and curvature, it’s not quite binary, but it’s close.
3. Denoise and cluster this matrix, and find updated estimates for the planes from this.
Tested on a face database, this worked very well. It misclassified only 3 faces out of 640. What’s remarkable here is that the Yale Face Database used had 64 different photos of each person, taken at different angles, different lighting conditions, etc. This has always been a hard problem for computer vision: how do you recognize that two pictures are the same person viewed frontal and profile, while two other pictures are of two different people? Apparently, this is a solution to such heterogeneity problems.
Geometric wavelets
The problem of dictionary learning is as follows. Given 
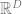
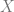
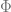
where 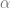

There’s a tradeoff here between the size of
One way of doing this is something called geometric wavelets. (Paper here. Shorter, more descriptive paper with cool picture here.)
Given a manifold, we partition it into a dyadic tree. We do principal components analysis on the coarsest scale and get a plane; then we divide that into two smaller subsets, do PCA on each of them, and get two new planes. For each plane, at the center point of that cube in the manifold grid, we have a tangent vector 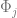

There’s a fast algorithm for computing this, very like the wavelet transform, except for a point cloud rather than a function. This is useful for compressing databases, analyzing online data, and so forth.
The idea is very like Peter Jones’ construction of beta numbers (summary here) except that it may be more efficient in terms of storage. More on geometric wavelets from Dan Lemire.
Multiscale Methods for Detecting Dimensionality May 2, 2010
Posted by Sarah in Uncategorized.Tags: high dimensional data, mauro maggioni, multiscale methods
2 comments
I’m currently reading this 2009 paper by Anna Little, Yoon-Mo Jung, and Mauro Maggioni, and it’s very lovely.
The idea is this: given a cloud of data, it may well lie on a low-dimensional manifold. But what dimension? We care about this because it indicates how many coordinates are worth looking at. To give an example (not the authors’, but I think it’s illustrative) psychologists like to give the Myers-Briggs personality test, which examines four axes (introversion/extroversion, intuitive/sensing, thinking/feeling, perceiving/judging.) But is personality best described by four coordinates? Or is it five, or three? What does the landscape of personality really look like?
If you have a linear mixture model, you can use PCA to find the rank of the data matrix. If you have a noisy linear mixture model, we’re still pretty much okay so long as the noise isn’t overwhelming, and that’s the (relatively) well-trod territory of random matrix theory. But estimating the dimension of a nonlinear manifold becomes difficult; PCA will tend to severely overestimate dimension. For example, the covariance matrix of a circle turns out to have two eigenvalues, but a circle, of course, is one-dimensional. In general, by choosing a curve that spirals out into many dimensions, it’s possible to construct a one-dimensional manifold with a full-rank covariance matrix. So we need to get more sophisticated.
Locally, of course, a curve looks like a line, so if we take a small enough radius we can determine that it’s one-dimensional. Small enough that the curvature isn’t much; but large enough that in the case of a noisy matrix the covariance is measuring the “true” manifold instead of the noise. Since we don’t know how big the radius should be, we take various radii and get singular values from all of them. This is what makes the method “multiscale.”
Try this with a noisy nine-dimensional sphere and you get the dimensionality rather nicely. At tiny scales there aren’t enough data points and the rank of the covariance matrix is far too low. At larger scales, the top 9 eigenvalues start to separate from the others; at even larger scales, curvature starts to matter and more eigenvalues separate. But it’s understandable that there’s a “sweet spot” giving dimension 9.
The authors go on to do some estimates of noise and find that the size of the noise in the covariance matrix is essentially independent of the ambient dimension.
The algorithm they come up with goes like this:
1. Compute singular values for the covariance matrix, for each radius r and each point on the data set;
2. Estimate the noise size from the bottom singular values that do not grow with r;
3. Identify a range of scales where the noise S.V.’s are small compared to the other S.V.’s.
4. Estimate which non-noise S.V.’s correspond to curvatures and which correspond to tangent directions by comparing the growth rate as being linear or quadratic in r^2. (The effect of curvature is to produce other non-noise S.V.’s — this is why linear methods tend to overestimate dimension — but these are distinguishable by their different growth rate.)
This turns out to outperform other existing algorithms which do not use this multiscale technique.
